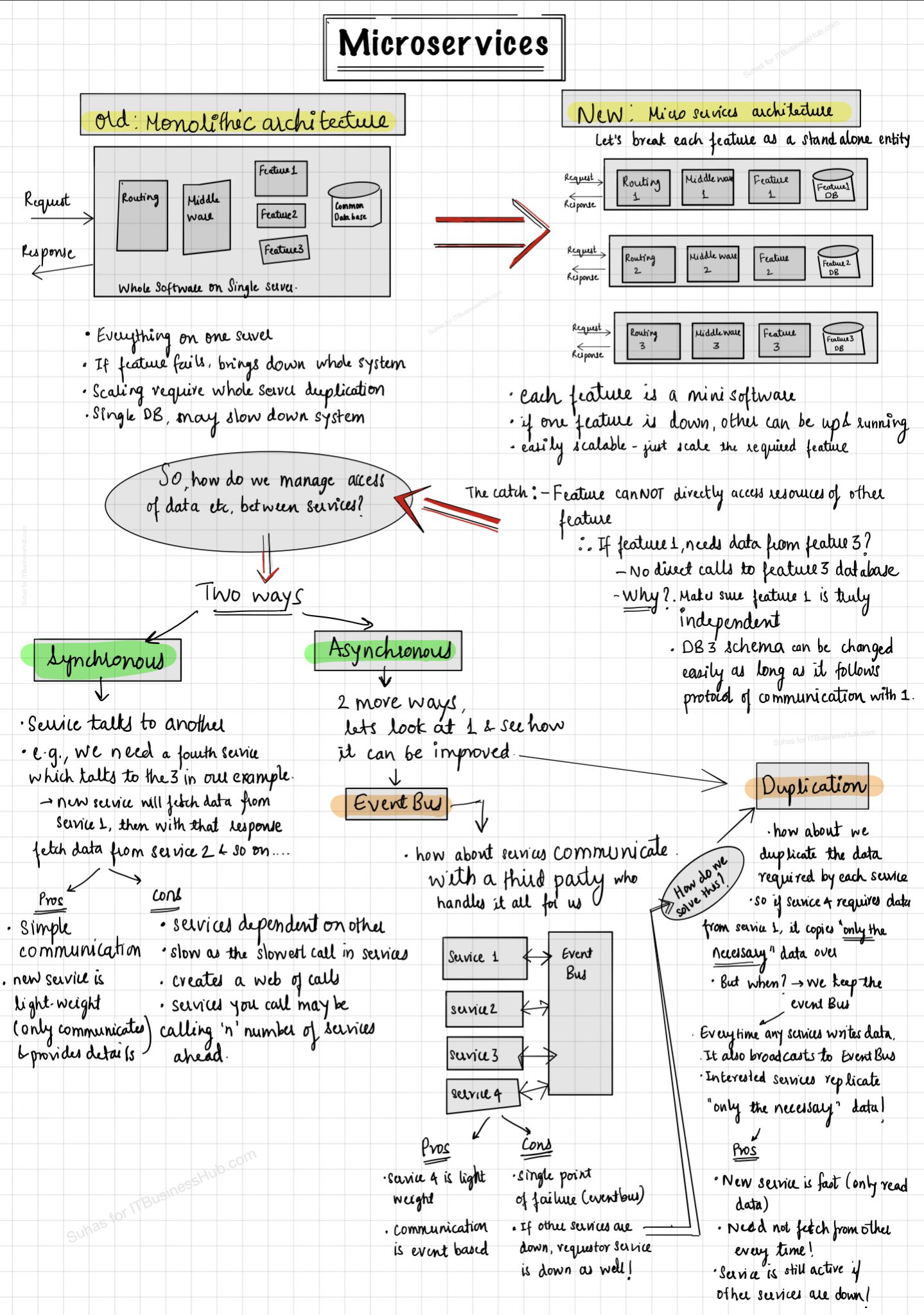
Microservices is one of the buzz word in the IT Industry lately. To be honest, Microservices is indeed and often confused with API services and all other sorts of terminologies that include the word ‘micro’ or ‘services’. Let’s have an in-depth view of what microservices are!
However, before we begin, we will need to understand the current ‘monolithic architecture’ of software development.
The monolithic software architecture
Up until lately, most of our software developed followed the monolithic architecture. (monolithic: built from a single material)
In a monolithic software architecture, one designs the application or software as a single material, where all the logic for all features in the software sits on a single server.
Let’s look at the diagram below.
An application say, that lets you browse products and purchase them.

In a typical monolithic architecture, one would include code that accepts the request from users, determines what “service” or feature user is trying to access, route them appropriately to the business logic, which may (if required) pull data from the big central common database and then routes the response back to the user.
The request to browse products as well as purchase products will route through the same application and then to individual business logic here.
Now, say if this server crashes- your entire application is down.
Or say, if a rogue code made its way to PRD, which supposedly slows down the database- will impact the entire application. Any other feature trying to access the same database will be slow as well.
In another scenario, say on a happy business day, your application gets lots of traffic, and you may want to scale up?- You will have to scale the whole application to another load balancing server. This server will duplicate your entire business code and the database.
But what if the traffic increase was only towards a certain “service” or feature of the application? Did scaling the entire application or software made sense?
Well, now you may see, where we are getting at…
What if we could break each feature of the application to its own service? What if every feature in your software is built and behaves as a separate entity on it owns, with its logic, routing, and even own database if needed?
Microservices explained.
Here comes Micro-services. Under microservices way of architecting our app, we shall build each feature as a stand-alone entity.
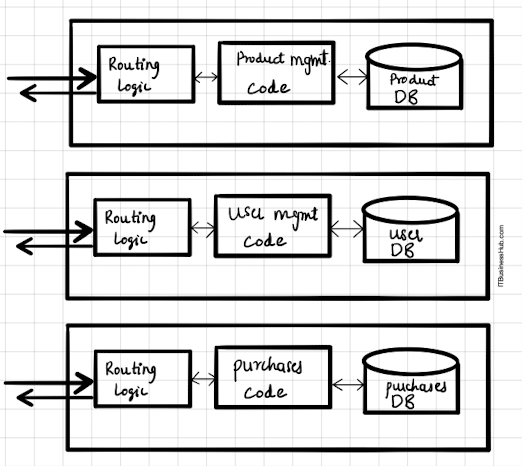
So, from our example app above, user details, product details, and the purchase details management code and database will be separate. They have their routing logic to call different functions within, have their features developed and own database.
So in this case, each feature is a mini software, independent and hanging in there, on its own.
If one of the service fails, other services may still be active, up and running. Say, if your products database went down, users may still be able to visit your app and register.
And on the day where your traffic doubled, and you had to scale ?; you could choose which feature needs to be scaled? Probably many visitors are registering on your site at the same time? Well- so just scale the servers that manage user registration code.
The other benefit of microservice architecture is you could have different teams developing different features of the software as a standalone feature.
Benefits of Microservices
So to list it quickly the benefits of microservices architecture would be:
- Independent services, less interdependence on other features in the app/ software
- Selective scaling of services
- Separate engineering teams for developing different services is possible
- Server crashes does not necessarily bring the whole app or site down
Microservices sounds cool, what’s the catch?
Well, now since we say each feature in our software or app is a stand-alone entity, one cannot build logic in one service that could talk directly to the components of other services.
Let me explain. In our example, the user service would be responsible to talk to users database and register users.
But say, if the purchases service from the app wants to access data about users from the user’s database? Nah !- That’s NOT allowed!
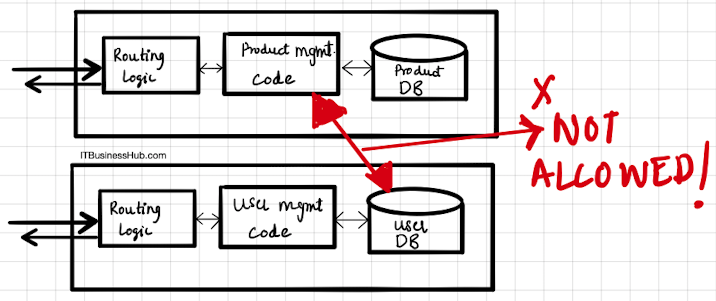
This goes against the basic principle of independent services. If we write code in the purchases service which tries to read users from the User service’s database, our purchases service will be dependant on it!
If the user’s database goes down- so does our purchases! Also, say if the user’s service team renames the details or schema of the database, the code from purchase service needs to be rewritten!
“Directly accessing the components of different service is NOT allowed under microservices architecture!”
Problems of Microservices
Data access management: In most cases of the software, one feature or service needs to access data that may primarily belong to other services. Given, the microservices way- we will separately have to manage this access.
Synchronous and Asynchronous way of managing microservices access
Now any service that needs to access details or components of other service needs to follow a certain protocol. We have two major ways of implementing this: –
- Synchronous, referring to services communicating with each other with requests
- Asynchronous, referring to services communicating with each other using a third party (Not directly, hence async. Not to be confused with asynchronous terminologies from the JavaScript world ) Asynchronous methods are further fine-tuned for efficiency, but let’s have a look at the synchronous ones to understand the pros and cons of each.
Synchronous method of microservice access:
Referring back to our example app of user service handling users, product service handling products, and purchase service handling orders.
Now say, if we need a new service that will list all the details of the products that were purchased by the user. Let’s refer to this service as orderDetails Service
So our orderDetails service - has to fetch the user ID from the users service, pull the purchased items for that user ID from purchase services and then pull the details of the relevant products from the products service.
Under the synchronous way of doing this, our orderDetails service will talk to each of this service and finally return us the details.
This is as simple as that. So what are the Pros and cons of synchronous way of handling this access?
Pros of Synchronous access:
- Is as simple as pulling data from each service in an ordered way
- OrderDetails service is light, so it does not have its database.
Cons of synchronous access:
- Dependence: As we might have noticed, orderDetails service is now dependent on all the other 3 services. So if any of these services are down, orderDetails service is also down!
- Network Calls: orderDetails services is making x (3 in our case) number of calls to pull the details. Even if one of this call fails at the network level, the final service fails
- Speed: The speed of orderDetails service is dependent on the slowest of the referred service.
- Web of services: We are creating a web of interdependent services. The services our orderDetails service calls, maybe further calling ‘n’ number of other services. This creates a big web!
Asynchronous method of microservice access: Event Bus
The asynchronous method has two types, but let’s look at the first one. In this method, we can define a third party that will help us manage access.
This third party code – known as “Event Bus”, will monitor for events. Any service which needs access will emit an event to the bus while all other services listen to events on this bus.

So in our example case, the orderDetails service will emit an event to the event bus asking for user details, which is picked by the user service.
User service then pulls the details and emits an event back to the bus, picked again by our new orderDetails service. This then continues, until our new service has all the details to form the final response.
So what are the Pros and cons of this approach?
Pros of EventBus Asynchronous access
- Our new service is still lightweight, no database of its own.
- Our new service could emit multiple events to various services at the same time, if it need not wait for other’s response.
Cons of EventBus Asynchronous access
- The web of requests still exists.
- Our new service will be as slow as the last event’s response to come in
- Single point of failure: By introducing “Event Bus”, we have created a new problem! If the event bus is down, all communications between our services go down!
Asynchronous method of microservice access: Duplication
Could we improve the asynchronous method of data access between microservices further?
Well, going back all the way to when we defined “microservices” architecture, our basic requirement was for each service to be independent of each other. Failure of one service should not necessarily bring down other services.
This approach may sound redundant to a few of us seasoned developers. But if you think the other way around, each service is a mini software of its own. So could we duplicate the database for our new service from the example? Yes- but with a twist! We duplicate only what we need!
Referring again to our example, the user’s service may handle logic to create new users and collect lots of user details in its database.
But our orderDetails service just needs the user ID. So if you could choose to replicate the user ID in our orderDetails database. Similarly only a few details of products and purchases will be duplicated in our orderDetails service’s database.

But, now- how do we make sure when and how the duplication happens! Event Bus is the answer!
Every time a user is created by the user service- it does it’s own business with its database, but also emits events to other services with the details.
Any other service that needs the details will then replicate and store it in their own database.
This way, we now have created a kind of truly independent orderDetails service.
Pros of duplicated database asynchronous microservice access
Speed: Our new service has its own database. So when the need arises to serve the user with data, it is as fast as reading the details from the database. Independent: Even if say the user details service or product service is down, our orderDetails service can be still up and running. There are no extra network calls to make every time the service is used.
Cons of duplicated database asynchronous microservice access
Duplication: Well as the basic requirement goes, duplication of data is a con in this approach!
Should you adopt Monolithic or Microservices architecture?
Now, that we know all the basic details of microservices architecture, would you adopt it? Although the duplication approach may sound weird to some, microservices has its advantages!
- Agility: With microservices way of developing software, each service or feature can be built separately by different teams of developers. This brings in better agility to the development cycle.
- Independent Testing: Each microservice can be independently tested for its features and changes.
- Availability: Since the software’s services can be independent, the product can still be partially available during downtime!
- Cost-efficient development and hosting: Business can focus on deploying resources towards the most critical services, hosting won’t be bloated as each service can be scaled independently.
While there are challenges to overcome under the microservices approach as well, organisations with a properly designed approach, thoughtfully organised teams, and excellent DevOps processes can innovate faster!
That’s all folks! Thanks for reading!
Here’s a brief summary of all that we discussed …