
If you have not heard about the 'Qwik' JavaScript framework, or you are exploring frameworks for front-end web development - one that is focused on performance, boots up instantaneously and can possibly load your site with about less than 1kb of initial JavaScript, then this post is for you.
Qwik is a new JavaScript framework, that is trying a different approach to reduce the amount of JavaScript, that is downloaded onto the user's browser whilst using modern web apps. To understand, how and what Qwik does differently, let's rewind a little to understand, how frameworks like Angular or React got popular.
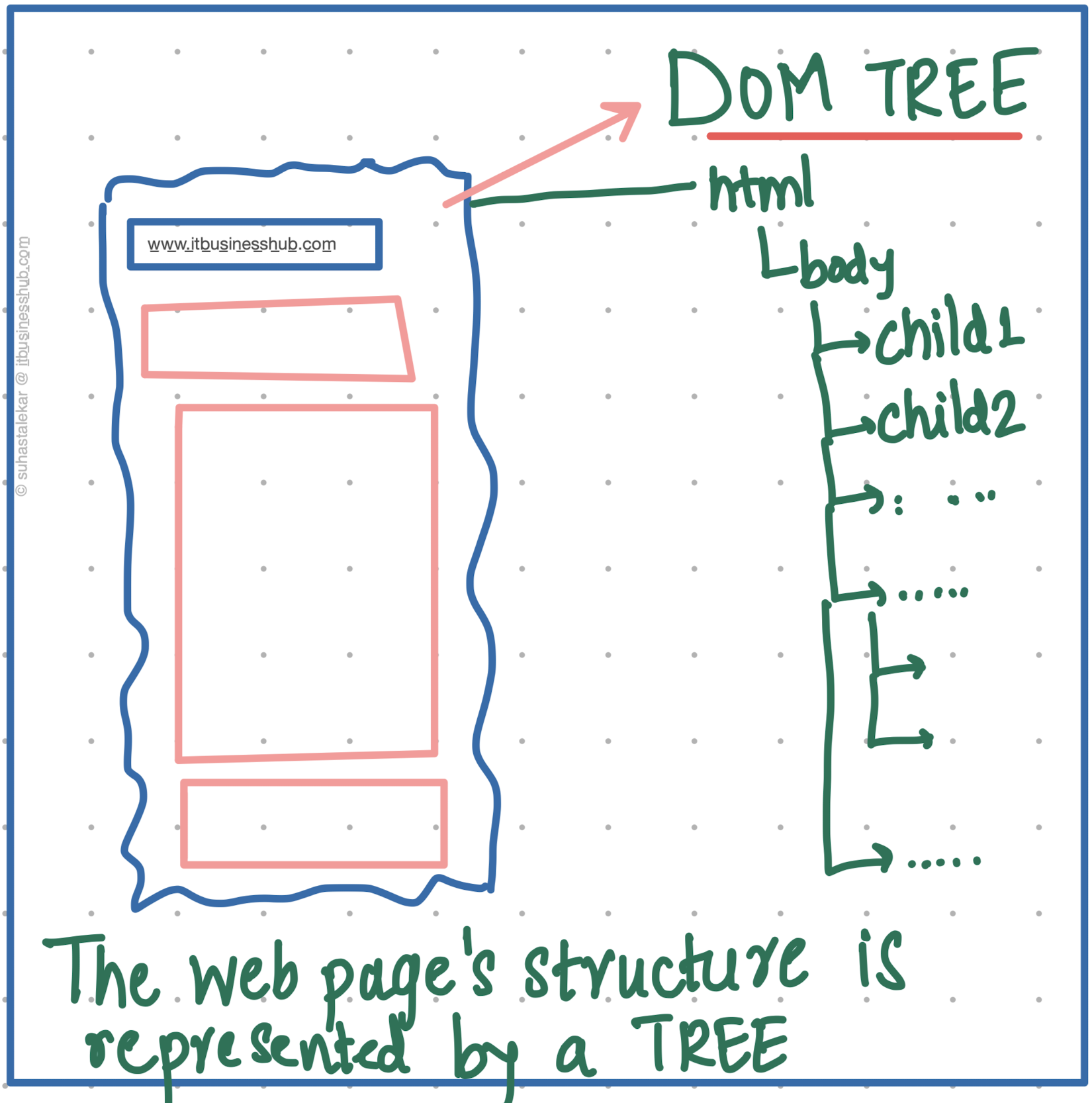
The necessity of growing the 'tree'
As web 'sites' started evolving into web 'apps', became more complex, and relied heavily on JavaScript, we had various single-page application frameworks spring into action. The approach taken by these frameworks was more of a 'declarative' type of JS programming v/s the previous 'imperative' type of JS programming- i.e., we started writing code that told the browsers what to do (declarative) rather than how to do it (imperative).
The responsibility of 'how to do it', was pushed onto these frameworks. Frameworks like ReactJS, for example, started with a concept known as 'virtual-DOM' (or 'incremental-DOM' in the case of Angular) i.e., keeping a separate track of the browser's DOM (Document Object Model: a data object-based - tree-like structure that tells the browser on how and the order of elements on the site are to be structured).
With virtual DOM in place, every time, a user interacts on the site or certain APIs change some data on the site, the virtual DOM assists the framework to watch for these changes and recreate the DOM for the browser. This makes the site responsive or 'react-ive'. A change or action by the user on some part of the UI is instantaneously rendered with updated data, everywhere else it is consumed. And with approach, we could build complex web apps, that need not be reaching out to the server for every new page view.
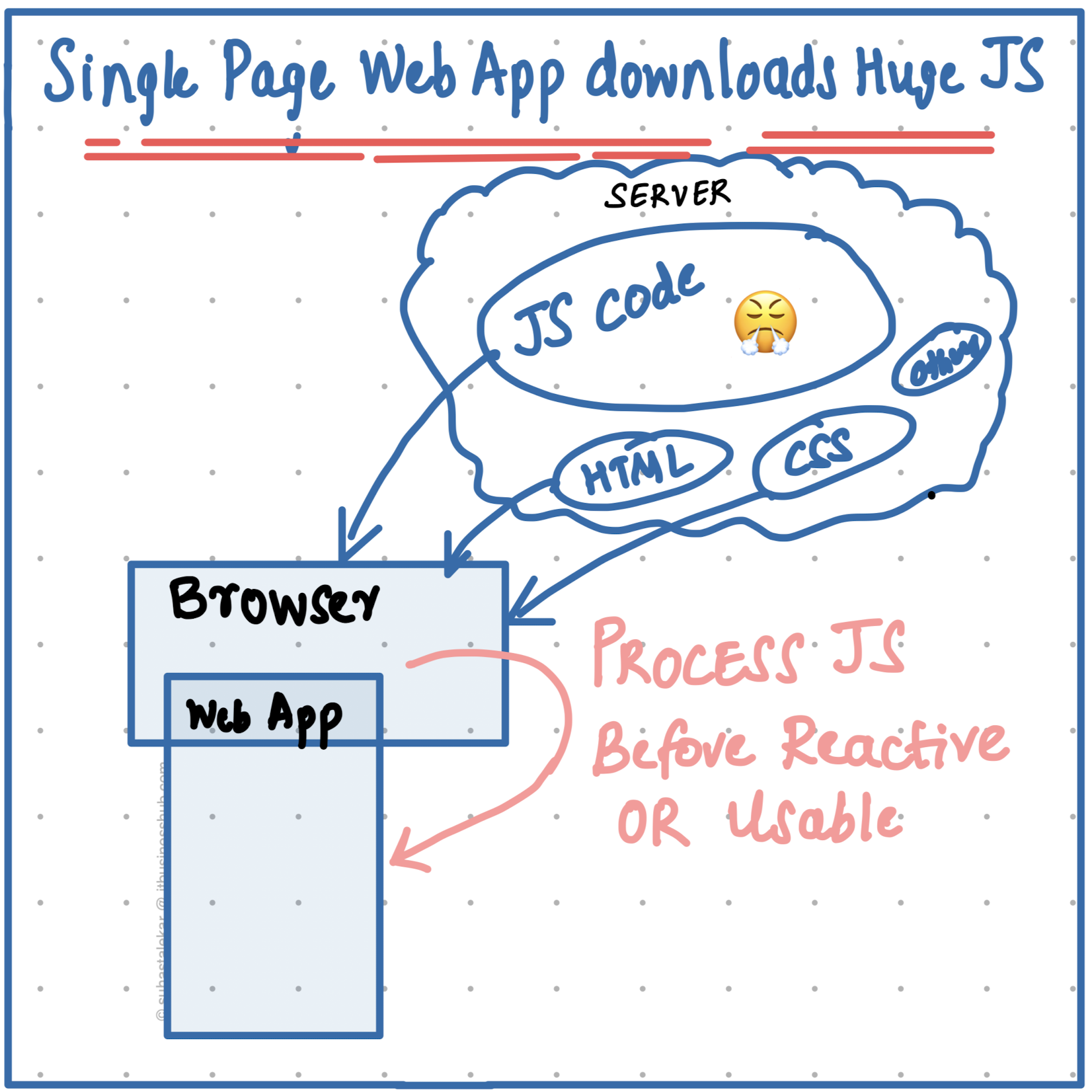
Complex apps: Shipping exponential amount of JavaScript
With the possibility of 'complexity of web apps', we started building lots of features on our sites/web apps. The tree grew! In other words, as we shipped more complex apps, the amount of JavaScript (even though we have techniques like minimising them), grew exponentially. The more the amount of JavaScript, the more the time it takes to load onto the user's browser, and the more time it takes to prep it to 'ready state' for user interaction- and -this was/is a problem!
It is HOT! We need to 'Hydrate'.
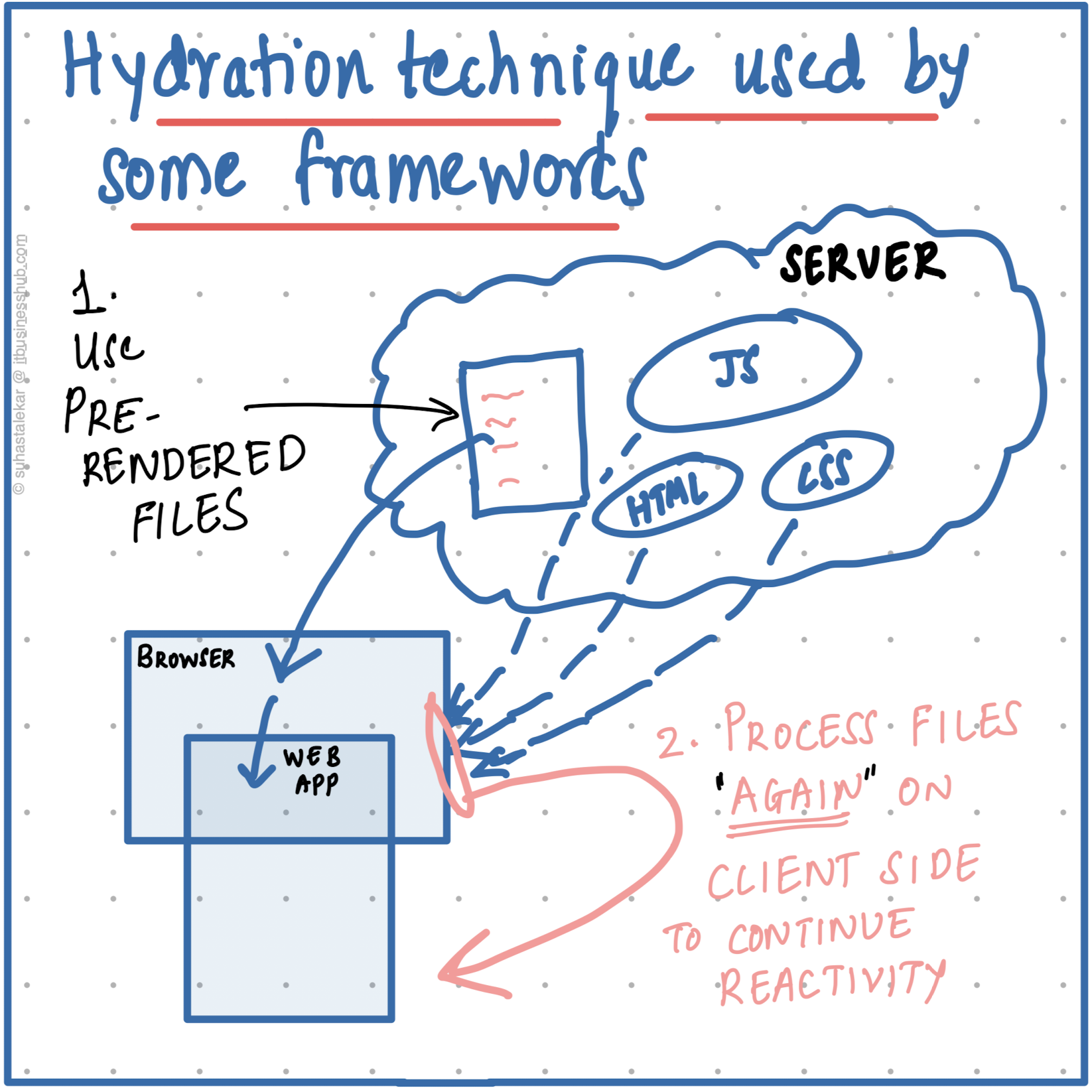
With an exponential amount of JS being processed on the client browser, we needed techniques to make the site usable before the large amount of JS is processed by the browser. In comes a concept known as 'Hydration'.
The generic idea of 'Hydration' is to process (pre-render) the basic structure of the web page on the servers (i.e., before it's passed over to the client's browser). Once the user sees the web page, we could then continue prepping the site for reactivity and finally be available when the user starts interacting with the site.
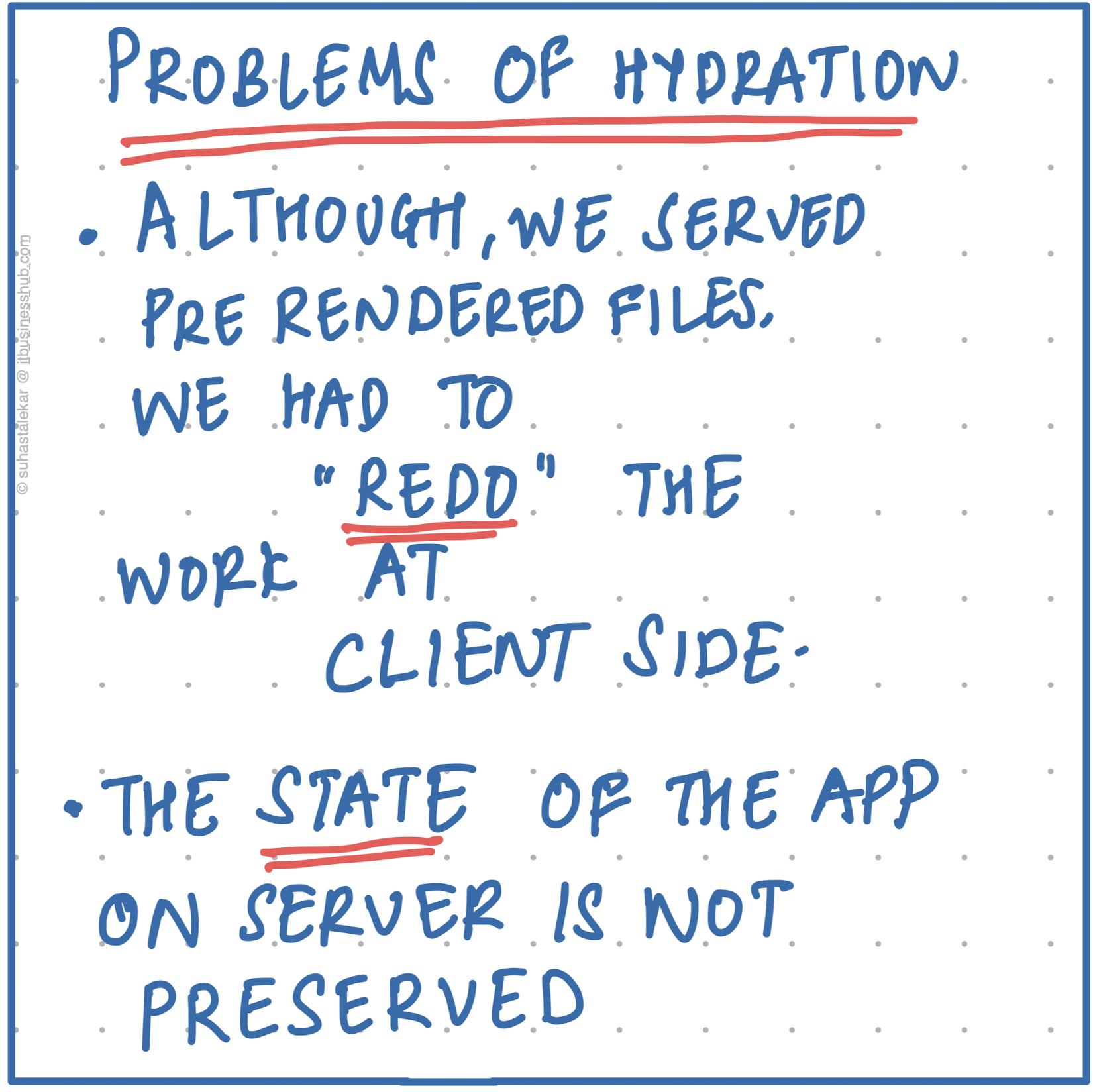
Hydration works, but has a few problems.
- Firstly, after the user has downloaded the basic pre-rendered site, the work done on the server, is again redone on the client side to make the site usable.
- Second, if a user loads a certain page, even if he or she does not end up utilising some of the features on that page, the code was downloaded as part of the page- and also re-built again.
Qwik Strategy: Delay JS execution
If a page is visited by a user, chances are he or she might not really utilise all the features on the page.
Let's say, you visit the home page of a certain website- but use its navigation link to route to a new page. The code that was written for some feature or form at the bottom of the home page, was never utilised but yet downloaded and compiled.
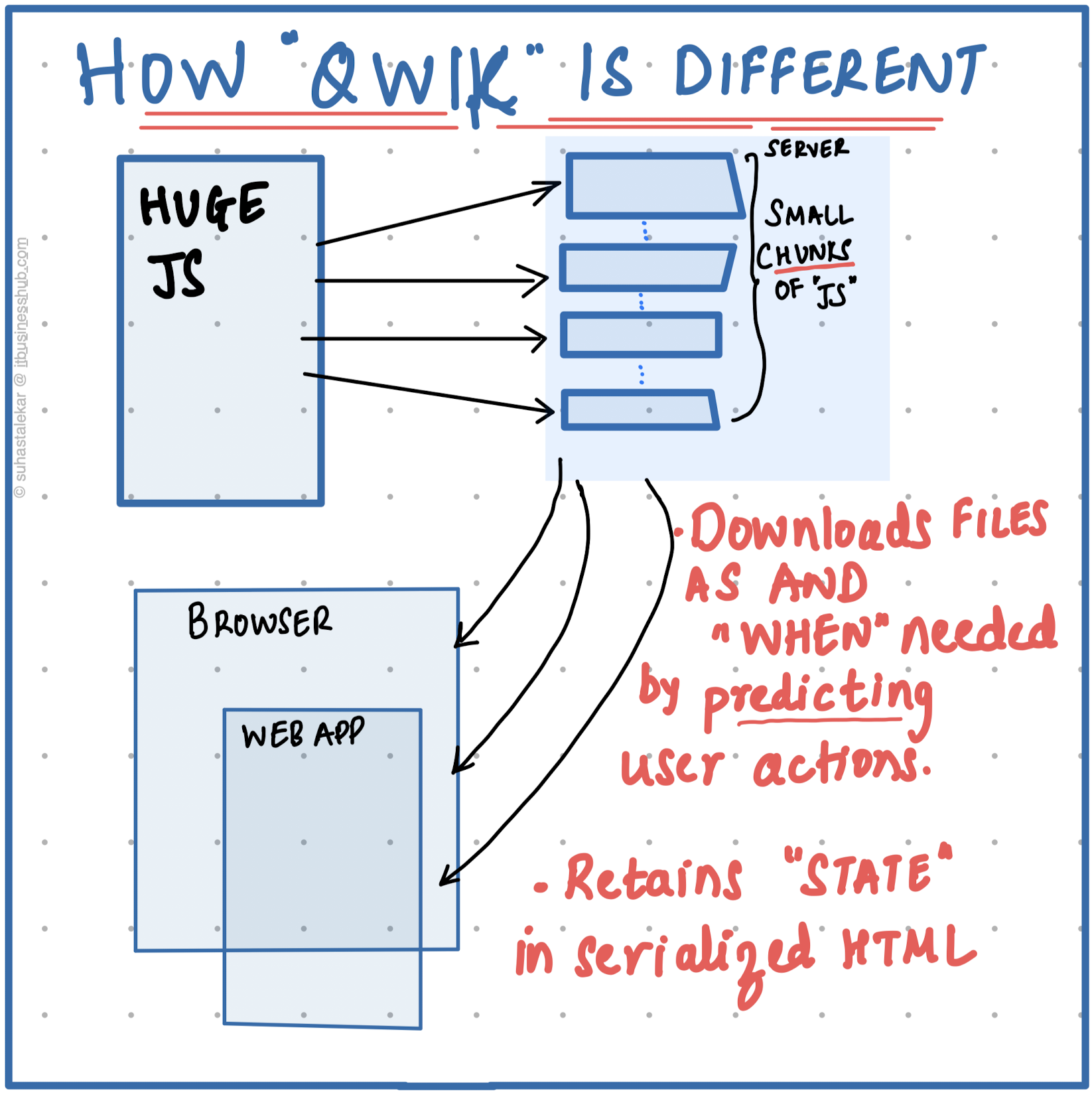
Qwik goes about by delaying the JS Execution. The framework splits the code into various chunks and downloads these chunks only, as and when needed. If the user scrolls below the fold, more chunks are predictively loaded that renders the features built below the fold. But if the user loaded the page and navigated to some other page, the JS code that was needed to render some feature at the bottom of the fold is never downloaded.
Qwik Strategy: Serialise the execution from server / Resumbility
If you recall the 'hydration' technique above, we pre-built the requested page on the server and handed it over to the client and then started working on the reactivity elements on the client's browser.
However, all the work that was done on the server- had to be redone on the client side.
With Qwik, the work that was done on the server can be serialised and stored in the HTML sent to the client. On the client side, the work is "picked up from where it was left", instead of redoing it all again at the client side.
With this strategy, Qwik components are faster to "resume" their work and be ready for user interaction.
Summary
Qwik's approach to minimising the amount of JavaScript shipped, by splitting them into chunks, as well as serialising the state in HTML to offer 'resumability'- certainly shows us a new way forward in the world of front-end frameworks.
You can read more about Qwik at 'https://qwik.builder.io' or follow their GitHub code at https://github.com/BuilderIO/qwik
Oh Yes, By the way- Qwik is an open-source project and also has a familiar face associated with it- Misko Hevery, is the same who created AngularJS.
Should you jump onto the Qwik framework?
Well, every tool has its purpose!
Qwik has its pros. But if you are already heavily invested in other frameworks, it would not be wise to throw away existing in-production projects, only to rebuild everything from scratch. A wise business decision based on the cost involved v/s the benefits for a particular use case of a site would make more sense. However, for new projects, you should certainly give 'Qwik' a try!